728x90
이번 글에서는 TensorFlow를 이용하여 Linear Regression 모델을 예측해보록 하겠다.

Quiz 1,2,3 점수와 Final 점수가 서로 선형 관계를 가지고 있다고 가정하고, quiz1과 quiz2 quiz3 점수가 들어왔을 때, Final점수를 예측하는 모델을 작성하려 한다.
TensorFlow 2.0 Anaconda Python 3.7.7 환경에서 진행하였다.
Source Code
import tensorflow as tf
import numpy as np
learning_rate = 0.00001
training_steps = 20000
tf.random.set_seed(777)
xy = np.loadtxt('score.csv', delimiter=',', dtype=np.float32)
X_DATA = xy[:, 0:-1] # 3 feature
Y_DATA = xy[:, [-1]] # result
W = tf.Variable(tf.random.normal([3, 1]), name='weight')
b = tf.Variable(tf.random.normal([1]), name='bias')
def predict(x): #predict
return tf.matmul(x, W) + b
for i in range(training_steps):
with tf.GradientTape() as tape:
cost_val = tf.reduce_mean((tf.square(predict(X_DATA) - Y_DATA)))
W_gradient, b_gradient = tape.gradient(cost_val, [W,b])
W.assign_sub(learning_rate*W_gradient)
b.assign_sub(learning_rate*b_gradient)
if i % 1000 == 0:
print("Step {:5} : {:5.3f}".format(i,cost_val.numpy()))
print(predict(np.array([[80,80,100]], dtype=np.float32)).numpy()) #quiz1 80 quiz2 80 quiz3 100 final ?
TensorFlow 2.0에서는 session이 없어졌다.
1.0에서는 결과값을 얻기위해 다음과 같이 코드를 작성하였다면
outputs = session.run(f(placeholder), feed_dict={placeholder: input})
2.0에서는 다음과 같이 함수를 지정하여 출력을 얻는다.
outputs = f(input)
아직 2.0환경에 익숙하지 않지만, 1.0보다 코드가 훨씬 간결해진 느낌이 있다.
결과값은 다음과 같다.
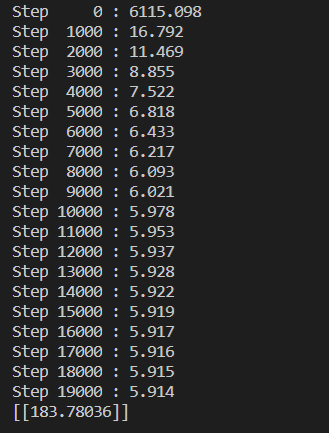
step 16000 이후에는 정확도가 크게 좋아지지 않는 것을 볼 수 있다.
여러가지 이유가 있겠지만
1. 완전한 선형관계가 아니다.
2. 학습 데이터가 적다.
3. 정규화를 하지 않았다.
등으로 최대 정확도가 5.5~6.0 정도 되는 것 같다.
Quiz1 80 Quiz2 80 Quiz3 100일때 예상되는 Final 점수는 183.78036점이다.
728x90
'AI > 머신러닝' 카테고리의 다른 글
| ML - Linear Regression(1) / Linear Regression이란? (0) | 2020.07.07 |
|---|---|
| ML - TensorFlow 설치(Anaconda) (1) | 2020.07.06 |

